Building a simple AI-powered, human-in-the-loop system to manage wildlife camera trap images & annotations
 Cougar in Purisima Creek Redwoods Preserve by Felidae Conservation Fund
Cougar in Purisima Creek Redwoods Preserve by Felidae Conservation Fund
In the summer of 2021, after three years of volunteering with Code Nation as an instructor and a brief stint with Code for SF, I was ready for something new! Wading through the web on a mission to find a new nonprofit, I stumbled onto a LinkedIn post from Felidae Conservation Fund. As their name suggested, they were a wildlife research & conservation organization that studied wild cats, specifically mountain lions. For someone who grew up on David Attenborough, the word "conservation" alone was enough to spark a sense of excitement but when I learned that they needed a cloud-based AI solution to improve their data pipelines, I was sold!
In this post, I briefly chronicle my journey designing and building this AI-powered, human-in-the-loop system to manage Felidae's camera trap images & annotations. If you're interested in the role of technology in wildlife conservation, building computer vision applications or working with nonprofits, you might find this post useful. If you want a high-level overview before jumping into this post, you can also check out this slide deck.
Keywords : Wildlife Research, Conservation, Artificial Intelligence, Machine Learning, Computer Vision, Object Detection, Human-in-the-loop, Annotation, Camerabase, Python, > > Django, Google App Engine, Google Cloud Functions, Dropbox, Annotorious, MegaDetector
1. Smile cougar, you're on camera!¶
Before we jump in, let's quickly cover what camera traps are and how they help wildlife research. Here's a TL;DR from this WWF post —
- Camera traps are cameras with sensors that detect activity in front of them and automatically trigger an image or a video capture.
- They let wildlife researchers gather data about our fellow creatures in a way that doesn't disturb their natural behavior.
Now, you're probably thinking, "but why can't we just walk through the forest and interview these critters as we do with our census and high five them at the end?". To that, I'd obviously say, "Great idea! I love to high five cougars!" but I presume the ecologists would be rolling their eyes. On a serious note however, "walking around the forest and gathering data" is actually a valid technique that I once volunteered to do over a decade ago, but it is an expensive, labor-intensive process and requires folks to tip-toe around the forest with the risk of, in my case, getting trampled into a pancake by unsuspecting, startled elephants!
While different techniques to collect data come with different tradeoffs, in the case of Felidae, camera traps are an excellent source since cats are typically shy and nocturnal. So, to support their research, Felidae operates well over a hundred camera traps, primarily in the San Francisco Bay Area, that generate hundreds of thousands of images every year!
2. The Data Supply Chain¶
While camera traps are great, the raw images they generate have some ways to go before turning into some sweet, sweet science we all love! Typically, researchers need to know
- where the image was taken - this is collected when a camera trap is set up by noting its latitude & longitude.
- when the image was taken - camera traps generate a timestamp for each image indicating when it was taken.
- what animal is in the image - once images are collected, annotators look at each image and make a note of the animals in it.
As you probably guessed, manually annotating these images is by far the most time-consuming process in this pipeline. But when you factor in camera misfires, errors, occlusions, blowing leaves, moonwalking leprechauns (ok I may have made this one up), etc., you're left with a lot of images that don't even have any animals in them! And if that isn't enough, just to mess with researchers, these camera traps occasionally decide to reset their internal clocks to some time in 1970 messing up all the timestamps. They just can't seem to catch a break! So, to manage this gnarly data pipeline, researchers/organizations set up different workflows depending on their size and access to resources.
To get a better sense for this, let's take a closer look at Felidae's data pipeline, the different problems they encounter, and the suite of tools used to address them. Broadly, their workflow can be split into three tasks —
- Set up camera traps - Camera traps are laid out at predetermined locations and to track them, Felidae uses Google Sheets to link a camera trap's ID with its latitude & longitude.
- Collect images - At regular intervals, memory cards from these camera traps are collected and transported to the office either over Dropbox or by physical mail. The Felidae staff then saves these images onto a physical computer along with information about the source camera trap.
- Annotate images - Felidae uses a Microsoft Access based tool called Camera Base to handle annotations. Since this runs on a single physical computer, access is restricted to a single annotator at any given time. So, annotators schedule access using a shared Google calendar and then remotely log in using TeamViewer to annotate images.
Once images are annotated and cleaned, data is exported out of Camera Base and distilled using R/Excel as needed to answer their research questions. This entire process is powered by a group of dedicated, hardworking folks comprising hundreds of volunteers and a small set of interns & full-time staff.
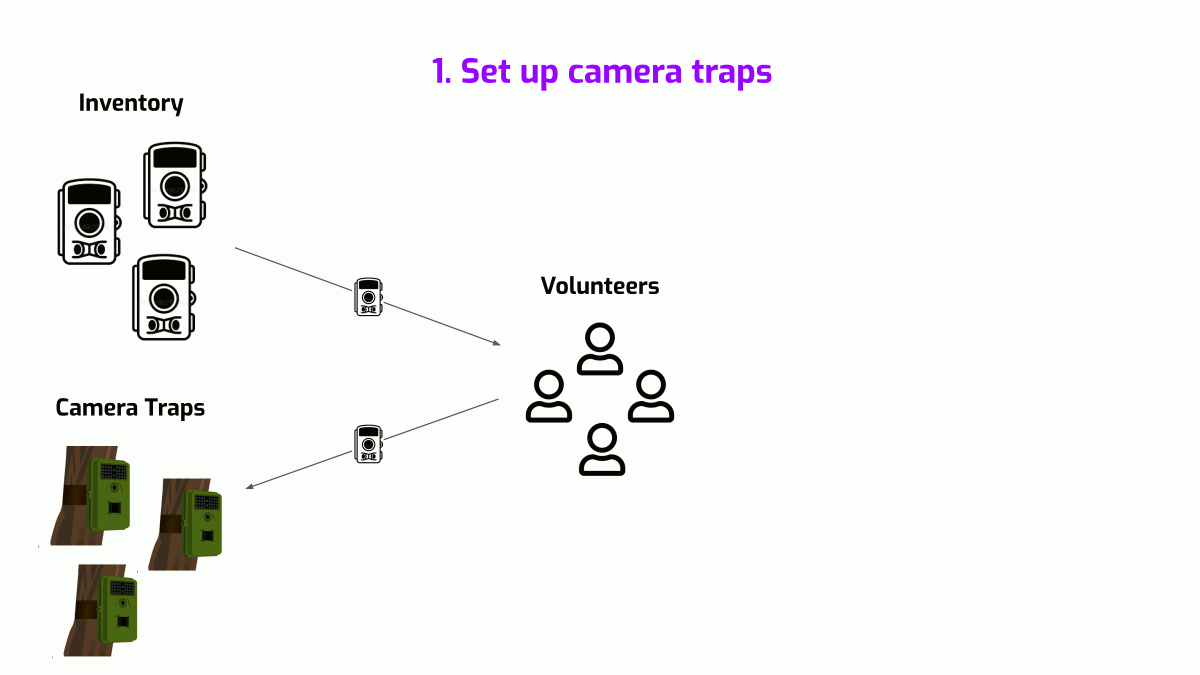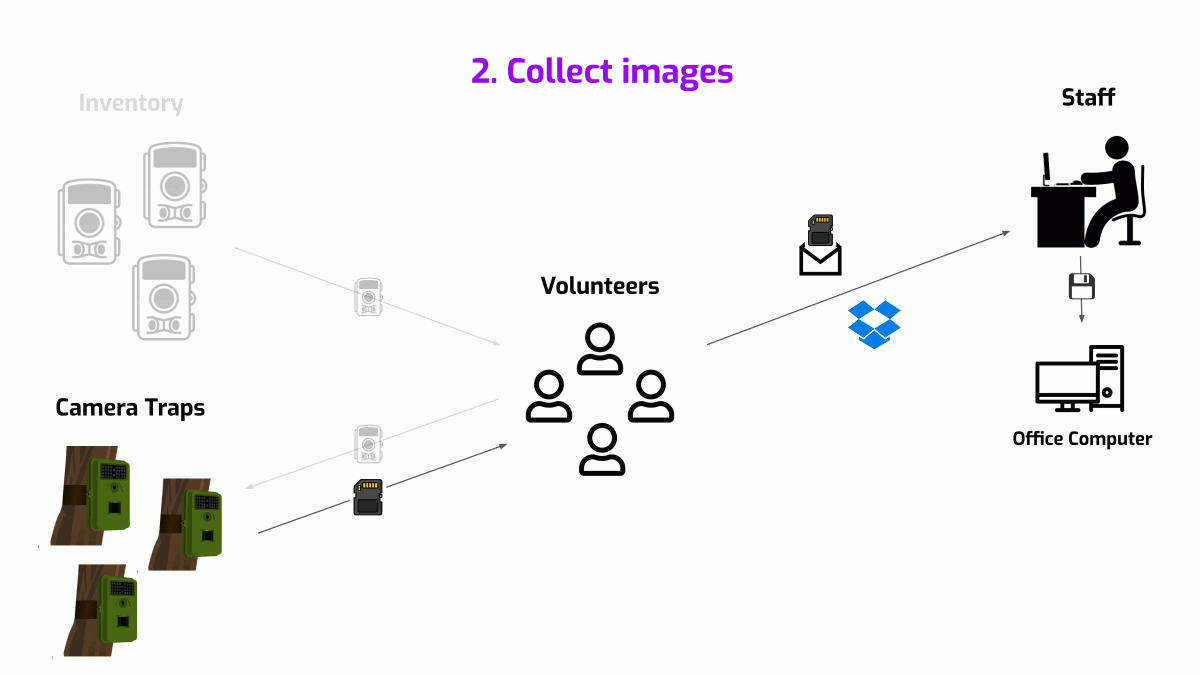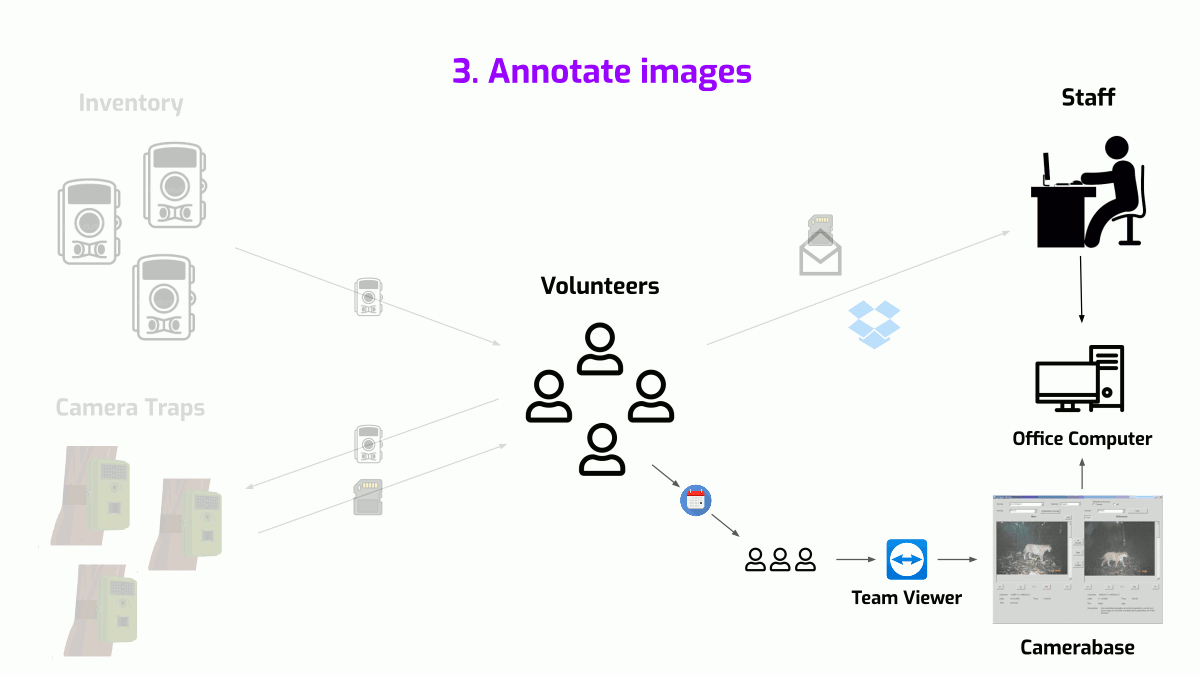
Felidae's data supply chain
3. Up, Up and Away to the Cloud¶
When I first learned about Felidae's workflow, this was my reaction — 😳😧💀 and my guess is, you're probably not far off now that you've learned about it too! I remember thinking, "Microsoft Access? TeamViewer? Shared Calendar? Did I just time travel?". But they knew that already! They were painfully aware of the inefficiencies in their workflow, especially their one-annotator-at-a-time bottleneck and the considerable backlog of un-annotated images it left behind. And not to mention the potential risk of hard disk failure and data loss! At the time however, they knew that moving to the cloud was the answer and had taken a shot at it but were stuck without a clear path forward.
3.1. The Holy Grail¶
Let's take a step back and look at the workflow again to find potential areas of improvement. The first, and the most obvious one, is moving away from Camera Base as the annotation tool, which, to be fair, was probably not built with simultaneous user access in mind. By building a web application to replace it, the annotation bottleneck can be eliminated by enabling multiple annotators to work simultaneously and independently. The second, less obvious one, is using Machine Learning, specifically Computer Vision, to automatically identify animals in the image. This technology has seen significant advances in recent years and with the potential to massively improve annotator throughput, it is widely considered a "game-changer" by wildlife researchers! So, from Felidae's perspective, progress in these directions would improve their workflow significantly and free up time to do more sciency things. But, as Morpheus famously says, "there’s a difference between knowing the path and walking the path", a difference more dicey in the case of nonprofits.
3.2. The Nonprofit Conundrum¶
It should be no surprise that nonprofits are resource-strapped, especially the smaller, more local ones. They have a hard enough time funding their core function that when it comes to investing in new technology, they tend to take a more conservative approach. Even when they lean ambitious, they often lack the in-house expertise to know where to start. As a result, they look to volunteers to come in and lend a helping hand! While this might look like getting "free work" at first, it comes with costs that aren't immediately apparent. Reality, unfortunately, doesn't hand out free lunch!
So, what are these costs? While not that different from what a for-profit organization might face, like attrition, onboarding, decision missteps, etc., the magnitude, however, is significantly amplified. Why? Because volunteers tend to have a day job and their availability & commitment levels are highly variable! Also, the pool of available volunteers is often shallow with a high degree of variance in experience, expertise & expectations. So when nonprofits experience flaking or ghosting from volunteers, their projects tend to stall, change directions or in the worst case, completely fail.
3.3. Highway to Integration Hell¶
Felidae's tech endeavors started in 2020 and had since seen a string of volunteers that worked on different aspects of their broader vision. The outcome was multiple threads of work at varying levels of maturity spanning a range of tech that closely mirrored the backgrounds of people that built them. Here's a quick look at what they were —
- A database schema connecting information from camera traps, volunteers, images, annotations, etc. drafted as raw SQL queries. It was well thought out but hadn't been in production yet and was sitting, dataless, on a $60/month Google CloudSQL instance.
- A partially built Node app that interfaced with this database. Most of the code, however, implemented basic CRUD (Create, Read, Update, Delete) operations on a handful of tables and was not deployed anywhere.
- A partially built React-based UI that hadn't been integrated with the back-end yet.
- A computer vision model trained in-house to separate images with and without animals in them. Distributed as raw PyTorch code that the staff had to execute on the office computer with a series of commands, this was the only component actively incorporated and provided a lot of value!
By summer 2021, when I first spoke to them, most of the folks who had worked on these threads weren't around. The remainder were trying to take these threads to completion and stitch them into a cohesive product for quite some time. What they didn't know at the time was that they were marching straight down the highway to what is fondly known as "Integration Hell".
4. Sometimes, a step back is a step forward¶
While it is reasonable to jump straight into a project on its existing trajectory, it is important to keep in mind that as someone new, you bring a fresh perspective that is relatively free from prevailing thought bubbles. While this empowers you to find more optimal solutions, it also makes you prone to repeating past mistakes! Needless to say, there was homework to be done and a lot of it!
4.1. Homework¶
Starting with no domain knowledge, I spent the first few weeks talking to some of Felidae's staff and past volunteers who were very gracious in helping me get a strong sense of what their workflows, pain points, and utopia looked like. They also chronicled, in detail, their current journey to modernize, the decision points along the way, and the rationale behind them. Since conversations like these tend to follow a narrative structure, I needed to separate what their problems were from the soup of how they tried to solve them or thought should be solved. And the best way to accomplish that was to produce a structured document that would serve not just as a written version of their oral history but also as a useful anchor for future conversations. Simply put, a review paper!
To complement this, I also had a fair bit of ground to cover about camera trap data pipelines in general which led me to discover this fantastic blog post from Dan Morris! It soon became apparent that Felidae wasn't alone in navigating what seemed like a fragmented landscape of software tools but what piqued my interest however, was the community's significant effort in recent years to address this very problem! Most notably, starting in 2018, using machine learning to automatically detect animals in camera trap images had been formalized as a competition at a workshop in CVPR, a popular computer vision conference. Also, Microsoft's AI for Earth had open-sourced one such model called MegaDetector for everyone to use! Another collaborative effort, Wildlife Insights, aimed to standardize camera trap image workflows by providing a cloud-based AI solution, something Felidae was attempting to build!
4.2. Bum first, Buy next, Build last¶
The urge to build something from scratch is not one that is easy to resist, especially under the seductive forces of flexibility & customization. After all, the desire to create is high, and so is the discomfort from constraints that external solutions impose! But, every decision is a trade-off and, with flexibility, come upfront and maintenance costs. As I mentioned earlier, these decisions are not unlike what for-profit organizations have to make but against the backdrop of rapidly advancing technology, higher churn and lack of in-house expertise, nonprofits have to do so under far greater levels of uncertainty making those costs more likely to be underestimated.
In other words, nonprofits face the same build vs. buy predicament that for-profit organizations face, albeit with slightly different constraints. On the one hand, they have a shallower pool of capital and labor to build or buy. On the other, thanks to the open source community, they have a deeper pool of free options to bum from! Given this context, a good rule of thumb is to first embrace a strong bias in favor of bumming free solutions while also relaxing quality thresholds. Following that is to look at buyable options, especially from large, mature organizations that offer low-cost, stable products with potential discounts dedicated to nonprofits. Lastly, resort to building only if (1) it is far too inefficient to adapt workflows to existing solutions and/or (2) there is an opportunity for reuse by other nonprofits.
Felidae, in their journey, had leaned heavily on the side of building far too many things and, with over 18 months of time and effort invested, had started to succumb to the infamous sunk cost trap. While it was clear that moving forward meant culling most threads of work and taking a step back, it was also important for me to be cognizant of the fact that proposals of radical change, especially from a new volunteer, would likely, and rightfully, induce fear and doubt. So, as I let time build trust, I worked on untangling what they had while nudging them towards external solutions even if it meant adding an extra step or two into their workflows.
5. Less is More¶
At a very high level, Felidae needed a single system that integrated the following functional components —
- Inventory management to catalog physical inventory like camera traps, boxes, memory cards, etc. and track their deployment in the field.
- Camera Trap management to track physical locations these cameras monitored during the course of their study period.
- Image management to store, browse and share the hundreds of thousands of images they collected in a simple, structured manner.
- Annotation management to tag these images with the animals they contain.
- User management for the volunteers and staff that collected, uploaded and annotated these images.
As mentioned earlier, Google sheets were used to keep track of inventory, camera traps & users; Dropbox/Windows File System managed images; and finally, Camera Base handled annotations. None of these, however, were linked to each other underneath, and doing so required a lot of manual labor! At the time, while there was no silver bullet to do-it-all (Wildlife Insights came close), there were, however, fairly mature sub-components backed by large, active working groups. So, the most reasonable option was to simply adopt those in place of in-house threads and pare things down to only a thin gluing layer, the web application.
My guiding principle here, molded by numerous hackathons, was one that favored speed. So, as I got started, my singular priority was to deploy a barebone but fully functioning end-to-end product as soon as possible. This approach was ideal given the context since it was imperative to bring end-users into the fold earlier than later into development. Also, as an internal app, there was a higher tolerance for bugs and glitches. But, perhaps more importantly, it offered something much needed at the time — a tangible sense of progress after 18+ months that would boost both morale, and recently placed trust!
5.1. Django Unchained¶
The central gluing component, the web application, had existed as thousands of lines of partially functioning code spread across SQL, Node & React. But to my surprise, most, if not all of it, simply implemented CRUD operations on base tables. While there were probably third-party packages in those frameworks offering the same functionality, neither I nor anyone else knew the ecosystem well enough to continue those threads. I did, however, have a fair bit of experience with another popular framework, Django!
Now, adding a new technology dependency is not something to take lightly especially when that dependency would trickle down to a single point of failure which, in this case, would be me! But, I was sure of my committment and given the situation, the risk seemed more than justified considering the numerous benefits that Django offered —
- A built-in GUI for basic CRUD operations, the Django Admin interface, and an array of skins to choose from (I use Jazzmin).
- A built-in user management system beefed up by the amazing django-allauth package.
- ORMs over raw SQL which I find simpler & cleaner (a personal bias).
- A single unifying language, Python, that would span the web app, the database and the AI/ML model lowering barriers for volunteers to contribute across different areas of the system.
Armed with this reasoning atop an undying love for Django, I dusted off my web development skills and got down to it. Luckily, just as I'd hoped, I was able to not just replace thousands of lines of code that existed but also add significantly more functionality with only about a hundred lines of code! And, just like that, over a few coffee-fueled evenings, I was able to stand up a web application that knocked out three of the five functional components — inventory, camera trap & user management — all thanks to amazing power of Django & the ecosystem around it!
5.2. More Dropbox, please!¶
The next, slightly trickier component was image management. The tricky bit here wasn't so much handling image uploads as it was the sheer volume of it! Straight outta memory cards, images would come in bursts of thousands and in some cases, tens of thousands which meant the web app would require functionality to pause/resume uploads, deduplicate images, verify image integrity and so on. Following that would be user interfaces to browse, share and manipulate these images. Unfortunately, the level of effort for this had been grossly underestimated by Felidae and they had lofty plans of not just building this but also layering in an in-browser ML model to filter out empty images before uploading. A pipe dream for a small nonprofit!
In line with the theme, my goal was to build less, not more. Luckily, this was a problem solved by pretty much any company that offered cloud storage and, as icing on the cake, Felidae had already been using Dropbox to transport their images. So, more Dropbox actually meant less work by offsetting their need to download images onto their office computer! More importantly, Dropbox came with two main advantages — (1) a simple, intuitive Python SDK for easy integration with Django and (2) an easy-to-use feature called "File Requests" that let even non-Dropbox users upload — making it an obvious choice over other alternatives like Google Drive.
From the user's perspective, once a memory card was collected from a camera trap, they simply had to log into the website and submit an online form (previously done on paper). Following that, they'd receive a Dropbox link to upload images. That's it! Behind the scenes, Django would then automatically look through uploaded images and add a thin layer of necessary metadata into its database. At this stage, Dropbox again proved to be extremely useful by exposing a suite of functionality through its API. Specifically,
- It made it easy to identify file types (images, video, documents, etc.) and for media in particular, it also exposed Exif attributes like timestamps and location (latitude/longitude) — critical for camera traps!
- It automatically generated content hashes to uniquely identify images.
- Lastly and most importantly, it offered a simple thumbnail API. This meant only smaller, compressed versions of larger source images (~5MB) could be pulled by Django for additional processing & rendering.
Less was definitely more!
5.3. MegaDetector & Annotorious, the Dynamic Duo¶
Lastly, and most critically, it was time to replace Camera Base with something more efficient. Broadly, this entailed two components — (1) a user interface for people to add annotations and (2) an AI/ML model that could learn from and replicate those annotators. Here, Felidae did have a win in the form of a trained model that could detect the presence of animals in an image with reasonable accuracy. But, they had completely missed MegaDetector, a similar model backed by a large community and trained on orders of magnitude more data. As an added bonus, while the in-house model attached a "blank"/"not blank" label to the entire image (image classifier), MegaDetector detected people, animals and vehicles along with their positions in the image (object detector). Needless to say, the axe had to come down on the in-house model and, with a new version of MegaDetector recently announced, that decision has clearly paid off many times over!
AI/ML models are tricky little creatures that make everything overtly stochastic and MegaDetector is no different. Without it, every image would need manual inspection and with it, images would have a probability of needing it! Unfortunately, interpreting these numbers is no easy task and uncaught error patterns at this stage have the potential to significantly skew downstream analyses. To be fair, human annotators are also stochastic with their own tenure-dependent error rates even if afforded a little more trust. So, a robust system would be one of collaboration where annotators wouldn't just cover blind spots from the AI model, but also each other — all while minimizing the amount of manual labor over time.
The first step in enabling this meant a user interface that would render bounding boxes that MegaDetector predicted while also letting annotators edit them or add their own. This is a common but important task in Computer Vision applications with entire companies built around providing such functionality and, while examining my options, I stumbled onto a free but pretty awesome library called Annotorious that seemed tailor-made! With a simple, intuitive interface, Annotorious made it trivial for the Django website to serve as an annotation platform and not just replace Camera Base, but also enable collection of more nuanced object-level data that MegaDetector and other AI-models could learn from!
5.4. FaaS, PaaS & IaaS¶
Since my priority was to build with Felidae staff in the loop, it was important to have the application live and accessible, even if in barebone form. So, decisions about underlying software infrastructure had to be made from the get-go. But before jumping in, let's take a step back and look at the different components of the system, only this time as pieces of software. Broadly, we have —
- the web application, Django, to serve as the primary interface for users to interact with the system.
- a relational database to house structured data about inventory, camera traps, users, images, and annotations.
- media assets primarily comprising compressed versions of camera trap images to render on the website.
- AI/ML models like MegaDetector to detect and identify objects in the image.
A decade ago, my instinct would have been to rent a bare-metal instance and stand all these components up but now, with a buffet of mature cloud services, there were a lot more options to choose from! With Felidae already having started off on Google Cloud Platform (GCP), the task boiled down to figuring out the right set of services to use while leaning strongly towards speed and ease of maintenance.
To start, using App Engine for Django was almost a no-brainer with its generous free tier, built-in autoscaling and great documentation to get started. Setting up a Postgres database was easy with Cloud SQL and its proxy made local development a breeze! For media assets, django-storages made storing to and serving from Cloud Storage trivial. And, along the way, Cloud Logging added a ton of visibility and made debugging a delight! This translated to the Django app going live as soon as it was built and made it easy for the staff to browse, grok and give their valuable feedback early on in the development process!
The remaining piece, MegaDetector, was a tad more tricky. For starters, since it was only triggered when large batches of images were uploaded, an event that happened a few times a month, it made no sense to bundle it with the Django app. Also, it had a large memory footprint (~6GB) that was well beyond App Engine limits. With that in mind, while I initially considered Cloud Run, I eventually landed on using Cloud Functions primarily due to its simplicity! With a simple http trigger, these cloud functions could be invoked by Django whenever images were uploaded and, decoupled from it, model development and deployment became more modular and independent. And, with that in place, the site was functionally complete and I totally did not scream "It's alive! It's ALIVE!!!" maniacally!
6. The View¶
By the start of 2022, after sporadic evening & weekend hack sessions in the preceding months, the site was ready! And, after a few months of staff-led user testing and ironing out UX kinks, the site had started to collect annotations by Spring '22. Zooming out, here is a quick look at what that meant for Felidae's workflow.
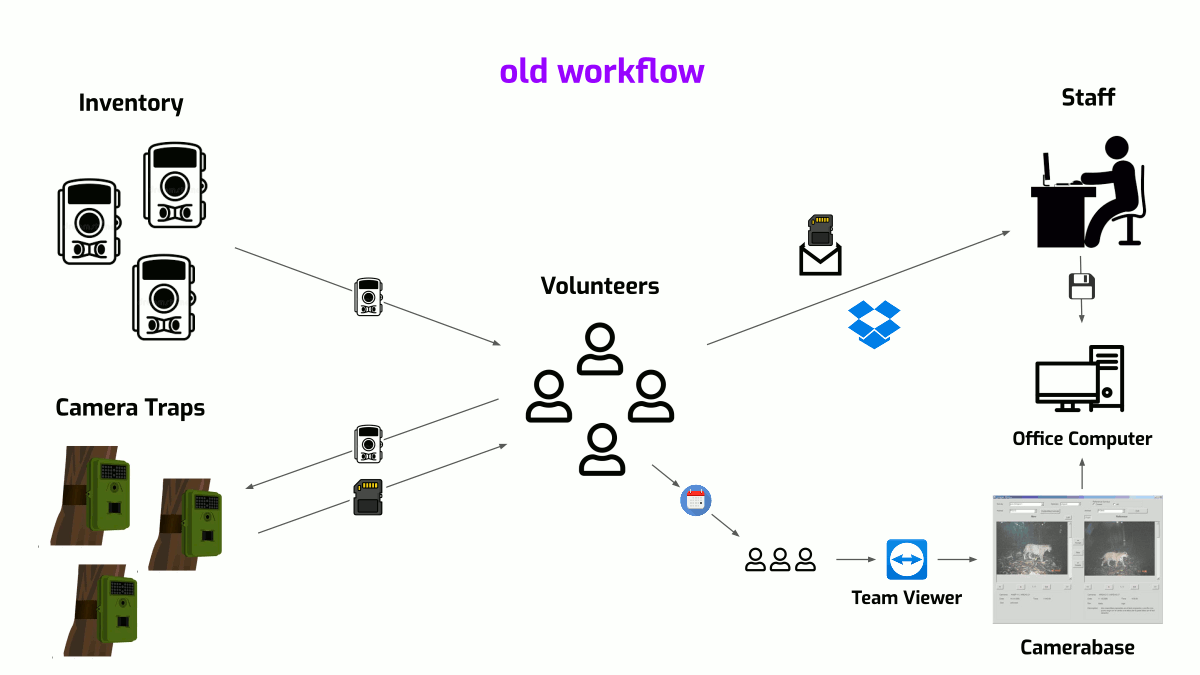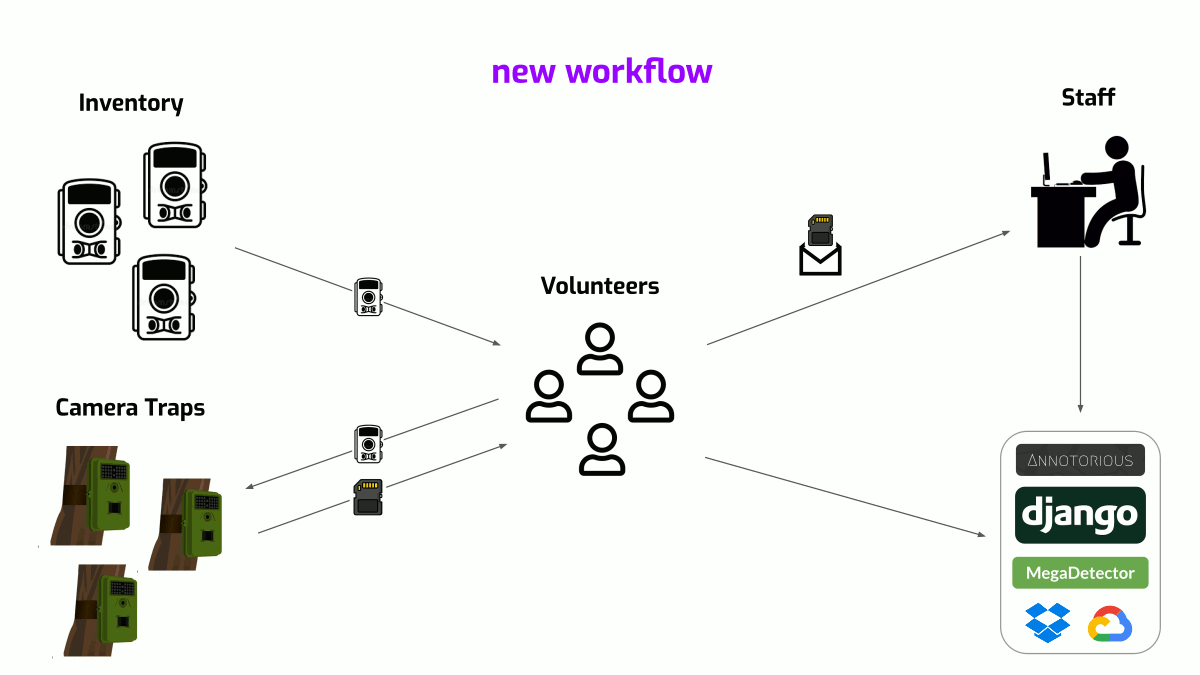
Felidae's old & new workflows
The site currently lives at WildePod.org and is currently gated to vetted volunteers with plans to open it up in the coming year! For now, here are some screengrabs to show what it looks like.

7. The trail ahead¶
The journey so far is really just a foundation for the interesting and impactful journey that lies ahead. With basic tooling in place, here are some broad areas of work that I think can create a lot of value not just for Felidae but also for wildlife research & conservation beyond!
- Data goldmine - Over the years, Felidae's camera traps have collected close to a million images, almost 5TB worth! Better yet, they also have a passionate group of volunteers who, using Camerabase, have painstakingly annotated a large subset of those images with both the species and the number of animals in them! So, the first step is migrating all those images into the new paradigm which, when stitched with MegaDetector, has the potential to generate hundreds of thousands of species-level annotations, an invaluable resource for ML models!
- Species detection - Currently, the use of AI/ML models in the app is limited to detecting animals in general. Accurately identifying its species, however, is a much harder task due to data sparsity and is very much on the bleeding edge of research. The current ramification of this is a two-step annotation process — a MegaDetector-assisted animal detection phase followed by a purely manual species-annotation phase where users have to select from a long list of species creating a slow and poor user experience. But, with Felidae's vast trove of in-house data, there is a big opportunity to not just improve species detection models for Felidae but also contribute to the larger research effort. And, in a classic human-in-the-loop fashion, trained models can greatly enhance user experience by simply sorting the list of species and in return, those user annotations can help models get better over time in a near-continuous, collaborative loop!
- Insights and analytics - Once images are collected and annotated, the last stage of this pipeline is often massaging data to answer research questions. At the moment, this is done by downloading annotations and loading them onto special-purpose software like Excel or R. While these tasks are generally harder to abstract, there is an opportunity to integrate high-level insights directly into the website freeing researchers to focus on deeper, more nuanced questions.
Underscoring this trail ahead is the opportunity to open-source data, model, and software resources to the wider community that could better help understand and help our fellow creatures in the wild!
If you're interested to help or if you have any questions, comments or feedback, please feel free to leave me a message on LinkedIn or add a comment below!
Citation¶
If you found this post useful, please consider citing it as follows: